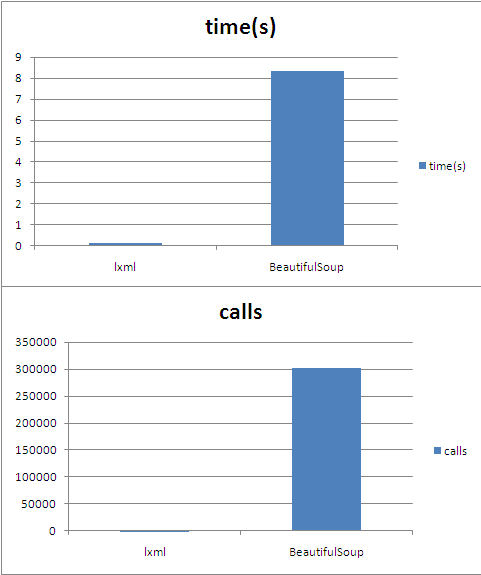
BeautifulSoup vs. lxml.html parser performance
Here is yet another little performance comparison between BeautifulSoup and lxml.html. Especially the comparison graph is really fun to see.
It's worth mentioning that the Python 3 edition of "Dive into Python" has a lot of rewritten and updated content. The thing that I like best about it is that it finally has an up-to-date chapter on XML that is entirely based on ElementTree and lxml.etree, the major XML libraries for Python. So, even for those who want to continue using Python 2 for a while, it's worth reading the new edition instead of the outdated Python 2 edition.
no_network parser option is set to False (obviously, network access is blocked by default).
I commented on this on the lxml mailing list in 2008 when there was a discussion about high web traffic at the W3C due to excessive DTD loading, which was also attributed to parts of the Python standard library.
The right way to handle this (in general, but especially for lxml) is to configure the XML catalogs on the local system. The libxml2 site has some documentation on how to do this. The advantage of using catalogs is that most XML tools will use them when available, so it is a system wide fix for the problem. Most Linux installations come with readily configured XML catalogs, but other systems may have to get fixed up.
Das sogenannte "Stuttgart 21" Projekt genießt ja inzwischen einiges an Medienbeachtung. Beachtlich finde ich daran aber vor allem, was für grobe und offensichtliche Fehler die Entscheider dabei gemacht haben. So wurden zuerst einmal zwei Projekte zu einem vermischt, die eigentlich nichts miteinander zu tun haben: auf der einen Seite ein neuer Bahnhof für Stuttgart, zusammen mit wesentlichen Änderungen an der städtischen Schienenverkehrsführung, auf der anderen Seite ein Neubau der Bahnstrecke Wendlingen-Ulm. Wahrscheinlich waren die Gründe dafür, dass für das eine ohne das andere nicht so leicht Gelder aufzutreiben gewesen wären. Bike-Shedding eben. Schließlich ist es leichter, ein Bauprojekt "unvorhergesehen" teurer werden zu lassen, wenn erstmal genügend Beteiligte mit im Boot sitzen - hier z.B. der Bund, das Land BW, die Stadt Stuttgart und die EU. Allerdings hat diese Verquickung auch gleichzeitig noch ein gigantisches Pulverfass mit eingekauft, das in den letzten Monaten hochgegangen ist.
Der nächste Fehler findet sich dann in den Verträgen. Da die Entscheider anscheinend jegliche Rückzugsklauseln vergessen (?) haben, bedeutet ein möglicher Abbruch des Baus nun einen Vertragsbruch, der entsprechend teuer zu bezahlen ist. Mit einem geschätzten Achtel der Kosten natürlich immer noch wesentlich günstiger als der Bau selbst, aber alles andere als kostengünstig. Unterm Strich würde ein Vertragsbruch und eine Beschränkung auf die Neubaustrecke Wendlingen-Ulm jedoch immer noch einige Milliarden Euro einsparen, ohne ernsthafte Nachteile mit sich zu bringen.
Und der dritte große Fehler ist die Außenkommunikation. Nur wenige sind dafür geschaffen, so resolut Probleme auszusitzen wie ein Helmut Kohl. Aber zur Schau getragene Ignoranz gegenüber einem realen Pulverfass verhindert eben doch nicht, dass dieses hochgeht. Dass die Stadt Stuttgart nun nach einem Kommunikationshelfer sucht, ist da eher ein Lacher am Rande. Daran hätte eher das Land BW Bedarf gehabt, und zwar vor etlichen Jahren. Die Außenkommunikation wirkte dermaßen arrogant gegenüber den Projektgegnern, dass sie praktisch keinen anderen Ausweg mehr zuließ als den zur Eskalation.
Ein ganzer Haufen selbst eingebrockter Süppchen also. Wenn es gut läuft, wird nur die Neubaustrecke vollendet, mit einem Vertragsbruchkostenzusatz von vielleicht einer Milliarde Euro und möglichen weiteren Kosten, da die Finanzierung neu aufgeteilt werden muss und sich die Stadt Stuttgart daraus wahrscheinlich zurückzieht. Vielleicht wird auch gar nichts gebaut, weil die Finanzierung in sich zusammen bricht, da sie plötzlich mit realistischeren Zahlen operieren muss als zur Zeit der ursprünglichen Entscheidung. Vielleicht bleibt ja auch alles beim Alten und die Bevölkerung in BW besinnt sich darauf, dass das bisschen Aufregung um ein paar Milliarden Euro mehr oder weniger noch lange nicht die Gefährdungen eines demokratischen Regierungswechsels rechtfertigt. Wer weiß. Aber vielleicht, ja, vielleicht lernt ja auch mal jemand etwas daraus.
Heute ist wieder Fremdballern bei der Gruppensportschau angesagt. Die Schlaueren unter uns nennen's einfach beim richtigen Namen: autofreier Samstag.
Christian-ich-werde-erst-Ministerpräsident-wenn-Schröder-weg-ist-Wulff ist jetzt Christian-ich-werde-erst-Bundespräsident-wenn-Mami-es-will-Wulff. Schön für das System Merkel, dass sich wieder einmal gegen alle Vernunft durchgesetzt hat. Schlecht für das höchste Amt im Staate, das so wieder einmal zu einem Spielball reiner Machtspielchen verkommt. Einen Vorteil hat die ganze Provinzposse aber: ein klareres Argument dafür, die Bundespräsidenten in Zukunft vom Volke wählen zu lassen, gibt es nicht.
Dann wurde ein Glasfenster im Schädeldach eingeklebt. So konnten die Forscher mit einem Spezial-Mikroskop an den lebenden Mäusen beobachten, wie sich das Netzwerk ihrer Nervenzellen verändert, als sie ihnen in den folgenden Wochen nach und nach die Schnurrhaare ausrissen und somit den Informationsfluss zum Gehirn unterbrachen.
Klingt wirklich nach einer ganz schön großen Baustelle im Kopf dieser Forscher. Könnte da mal bitte jemand die Bauaufsicht benachrichtigen? Danke.
Eine wunderbar treffende Karrikatur der Berliner Zeitung zur aktuellen politischen "Situation" in Berlin.
Besides any() and all(), Cython also has support for inline generator expressions in sum() now - and it's fast!
CPython 2.6.5:
timeit "sum(i for i in xrange(10000))"
1000 loops, best of 3: 584 usec per loop
# Cython 0.13-pre:
def range_sum_typed(int N):
cdef int result = sum(i for i in range(N))
return result
timeit "range_sum_typed(10000)"
100000 loops, best of 3: 2 usec per loop
Obviously a really stupid benchmark, but still - that's what I call a difference!
Here's another benchmark for looping over a fixed list of Python integers instead:
# CPython 2.6.5: timeit -s "r=range(10000)" "sum((i*i for i in r), 100)" 1000 loops, best of 3: 868 usec per loop
# Cython 0.13-pre:
def typed_sum_squares(seq, int start):
cdef long i, result
result = sum((i*i for i in seq), start)
return result
timeit -s "r=range(10000)" "typed_sum_squares(r, 100)"
10000 loops, best of 3: 49.9 usec per loop
Not exactly what I''d call "closer". ;)
I'm really happy about all the new Unicode and type inference features in the upcoming Cython 0.13. It finally has support for CPython's Unicode code point type, Py_UNICODE, and can transform various operations on Unicode characters into plain C code. For example, this will run as a plain C integer for loop:
def count_lower_case_characters(unicode ustring): cdef Py_ssize_t count = 0 for uchar in ustring: if uchar.islower(): count += 1 return count
Or, if you only want to know if there are any lower case characters in a string at all, here's another plain C solution:
def any_lower_case_characters(unicode ustring):
return any(uchar.islower() for uchar in ustring)
The latter is actually somewhat of a fake as Cython does not generally support generator expressions yet. However, it still shows where the language is going. In the examples above, Cython can infer that the loop variable can only ever hold a single Unicode character, so it can safely map the entire loop into C space. IMHO, a beautiful example that the integration of Python objects and C types is getting so tight that even totally innocent looking code starts running at the speed of light.
{kind=link}